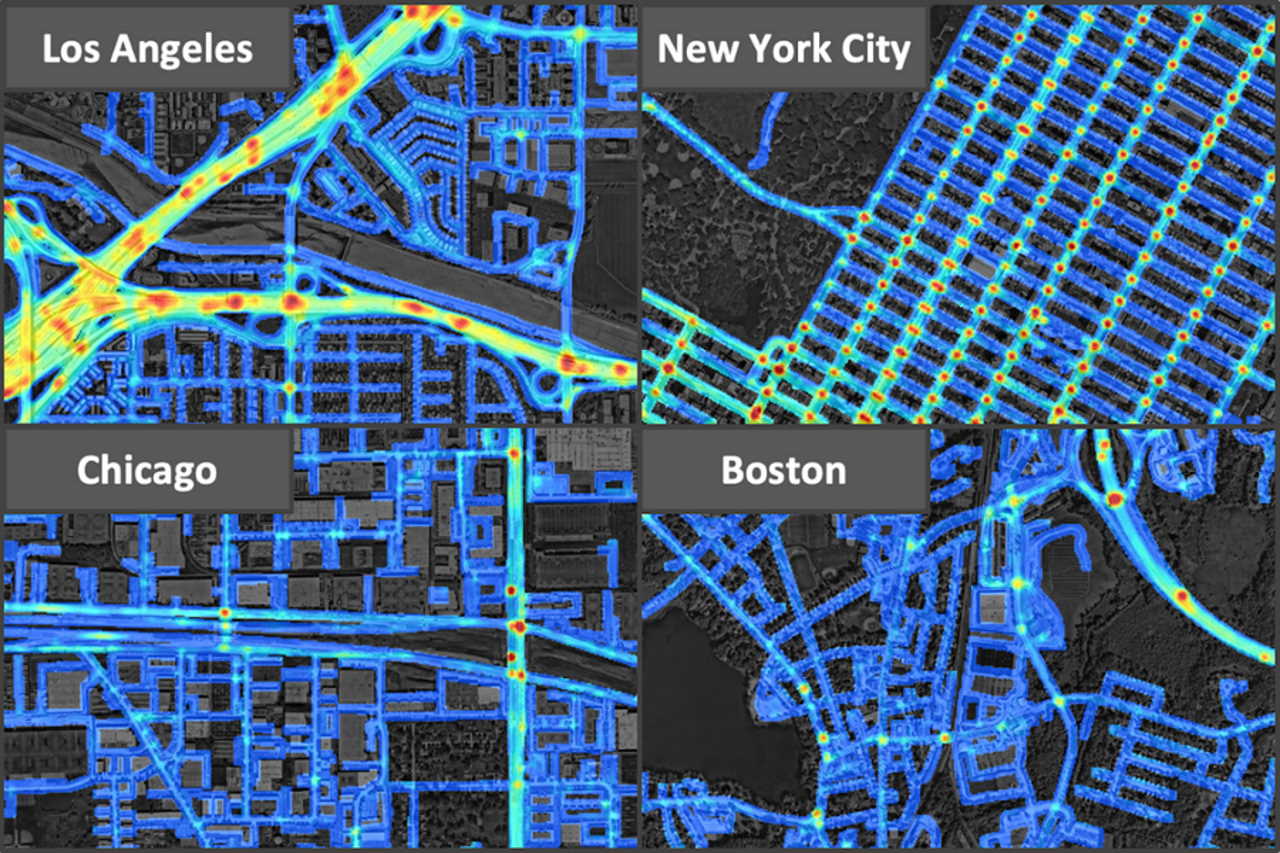
Розробники з MIT розробили модель глибинного навчання, яка передбачає ризик аварій на дорозі для автопілота в авто. Вона спирається на дані про ранні ДТП, з дорожніх карт, супутникових знімків і популярних маршрутів за GPS. Так вона визначила зони підвищеного ризику Лос-Анджелеса, Нью-Йорка, Чикаго і Бостона. Алгоритм вчені представлять на Міжнародній конференції з комп'ютерного зору.
Songtao He et al. / MIT CSAIL
Як розрахувати імовірність ДТП?
За даними ВООЗ, внаслідок дорожньо-транспортних пригод гине щорічно 1,35 мільйона людей, а від 20 до 50 мільйонів отримують несмертельні травми. Дорожньо-транспортні пригоди складають близько трьох відсотків світового ВВП. Наприклад, за підрахунками Світового банку, соціально-економічні втрати України від дорожньо-транспортного травматизму оцінюються в майже 70 мільярдів гривень на рік. Виявляючи на карті місця з високим рівнем ризику, водії, транспортні департаменти і страхові компанії можуть вживати заходів для зниження цього ризику. Так звані мапи ризику присвоюють очікувану частоту нещасних випадків за певний період часу для кожної точці на карті. Їх і вирішили навчити складати штучний інтелект розробники з Лабораторії комп'ютерних наук і штучного інтелекту MIT. Для оцінок у точках п'ять на п'ять метрів мапи, модель поєднує дані про ранні ДТП, з дорожніх карт, супутникових знімків і популярних маршрутів за GPS, що, на думку вчених, дає їй змогу давати найточнішу оцінку серед інших подібних алгоритмів.
Як передбачає ШІ?
Як ми вже вказали, мапа ризику є сукупністю інформації з різних джерел про умови на різних ділянках дороги, тому враховувати велику кількість параметрів і робити на їхній основі припущення, є ідеальною задачею для штучного інтелекту. Втім, попередні роботи або оцінювали карти низької роздільної здатності, тобто намагалися охопити велику територію, що знижувало продуктивність через високий ризик систематичної помилки, або використовували методи оцінки на основі частоти ДТП, які не могли точно прогнозувати, де насправді відбуваються аварії через високу дисперсію у даних. Але і передбачити аварії на менших ділянках, тобто вищої роздільної здатності, складно, адже так збільшується кількість шуму у даних. Причому аналіз набору даних про дорожньо-транспортні пригоди у США показує, що 31 відсоток ДТП відбувається у місцях, де не було інших аварій в межах 50 метрів протягом чотирьох років. Тому карта майбутніх нещасних випадків як оцінка методом Монте-Карло базової частоти нещасних випадків, містить велику кількість помилок в оцінюванні ризиків. Метод працює тільки в тих місцях, де є достатня кількість даних про аварії.
Мета нової ж нейромережі в прогнозуванні ризику аварій не полягає у тому, щоб точно визначити, де відбудуться нові аварії, тому що це неможливо. Замість цього вона прагне визначити основний ризик нещасних випадків в кожному місці карти, незалежно від того, відбулися в них нещасні випадки чи ні. Вона використовує прихований ризик нещасних випадків як основну істину. Під час оцінювання ризику алгоритм недооцінює ризик небезпечного перехрестя і переоцінює ризик безпечної вулиці, що дозволяє впоратися з розрідженістю даних.
Що передбачила нейромережа?
Компроміс між роздільною здатністю і точністю вчені спробували обійти глибинним навчанням моделі, яка використовує контекстну інформацію з супутникових зображень, траєкторій GPS і дорожніх карт. Так росте ефективність вибірки, на основі якої модель буде будувати свої передбачення: вона буде не просто зіставляти дані про минулі ДТП з дорожньою картою, а й порівнювати їх з супутниковими знімками. Адже якщо на одному перехресті сталася аварія, то можливо розділити деякі ризики з аналогічними перехрестями. І саме щоб зробити узагальнення від одного перехрестя до іншого, нейромережі потрібні ці додаткові дані, які допоможуть зафіксувати додаткові подібності між перехрестями. Наприклад, траєкторії GPS несуть інформацію про щільність та швидкість трафіку, а супутникові зображення містять інформацію про дорогу: кількість смуг, чи є узбіччя та чи багато пішоходів.
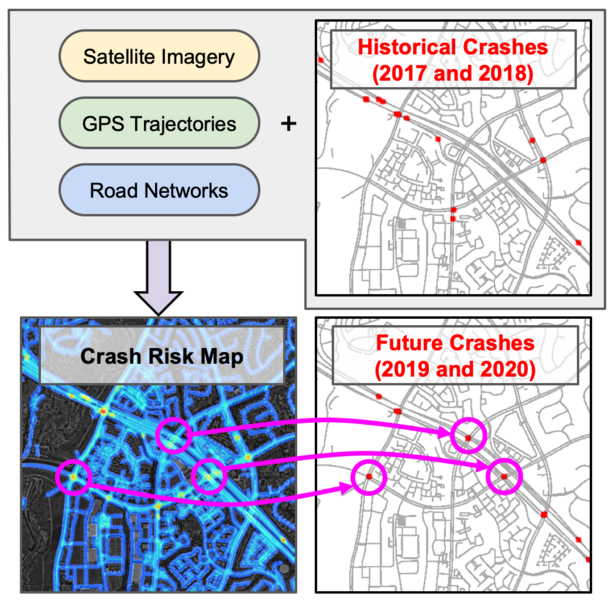
Передбачення нейромережі. Songtao He et al. / MIT CSAIL
Модель дослідники оцінили на наборі даних про 7 488 квадратних кілометрів чотирьох мегаполісів: Лос-Анджелеса, Нью-Йорка, Чикаго і Бостона. Набір даних організований у вигляді 1 872 плиток два на два кілометри, для яких зібрали супутникові зображення, популярні GPS-траєкторії з 2015 по 2017 рік і 4,2 мільйона записів про аварії з 2016 по 2020 роки. Кожен запис містить координати і часові мітки. Вчені розділили цей набір даних про аварії на дві частини: ті, що містять дані за перші два роки і дані за останні два роки. Дані за перші два роки віднесли до «історичних» — за ними нейромережа зробить свої передбачення. Їх перевірять за даними за останні два роки. Серед чотирьох міст Лос-Анджелес виявився найнебезпечнішим, оскільки у ньому була найвища щільність аварій, за ним слідували Нью-Йорк, Чикаго і Бостон. Вчені пропонують використовувати свою нейромережу для покращення планів міського планування до початку будівництва, а також для створення просторово-часової моделі ризику аварій.
До речі цьогорічну Нобелівську премію з фізики присудили за моделювання хаотичних явищ, а зокрема за просторово-часову кліматичну модель та модель впливу вуглекислого газу. А також нещодавно ми розповідали про штучний інтелект від DeepMind, якому вдалося передбачити дощ у найближчі півтори години.




